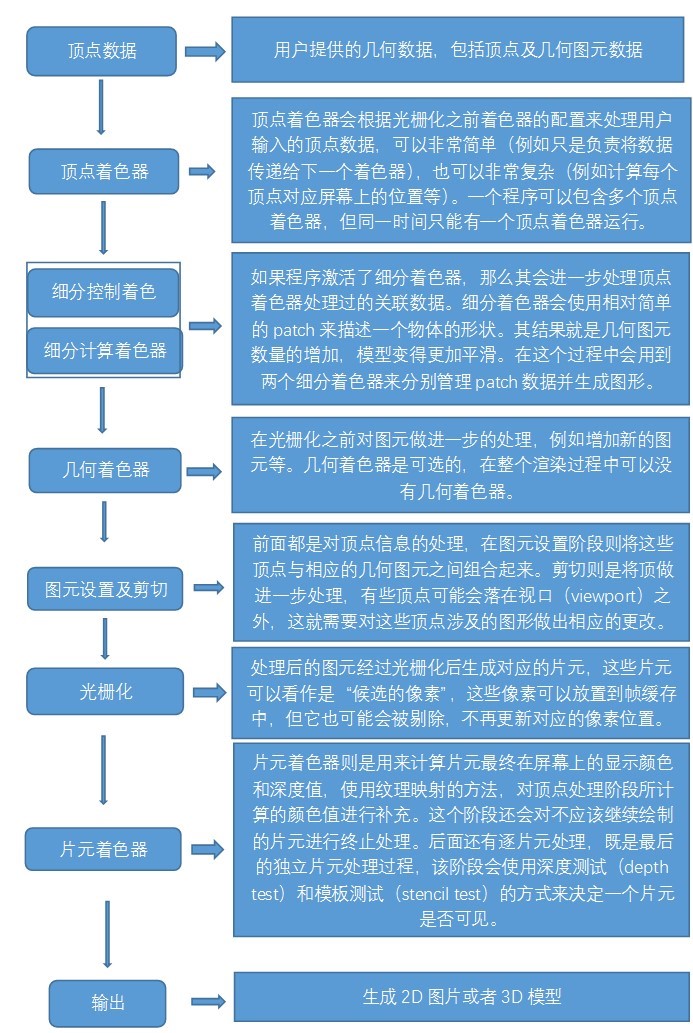
参考教程
系列视频:https://www.bilibili.com/video/av11263377
本文的知识点将只包括numpy数据的基础使用方法,将会涉及到如下内容:
- numpy ndarry基本数组的生成
- 数组深浅拷贝
- 数组的基本形状改变
- 指定维度上的计算
- 不同shape也可以运算的操作
- 数组的增删操作
- Mask array的一些特性
- 小数数组打印的技巧
不过本文是属于查漏补缺性质的,重点在那些容易忽略的地方,而那些大多数人都知道的部分就不会再细写了。
linspace函数的使用(数组初始化)
之前的工作中,创建numpy的数组我一直都习惯用arange、zeros、ones这几个函数,而对linspace这个函数却不是很熟悉。linspace与arange的作用有些相似,都能生成等间隔的数组,但是两者有如下区别:
- 需要固定步长用arange,而需要固定生成数目的个数用linspace,因为linspace会自动计算步长,设置retstep参数可以返回计算的步长
- arange生成的数组不包endpoint的值,而linspace则包含
1 | np.linspace(0, 15, 5, retstep=True) |
view和copy(浅拷贝与深拷贝)
view时浅拷贝,copy时深拷贝,在我的一般使用中只用copy就可以满足了,不过其实view也有比较好的应用场景,如同一数组希望用不同维度或不同的类型的形式使用,下面代码,arr_v2是arr_v1的view,但是在使用Ⅹ不仅将其纬度改变了还将其元素类型也改变了,对arr_v2的修改会影响arr_v1:
1 | arr_v1 = np.array([1,5,10,15,20,25]) |
修改reshape
1. reshape
shape相关的函数最常用的就是reshape了,但是注意:reshape函数是view而不是copy
2. ravel函数和flat属性
ravel将多维数组转为一个一维数组, flat属性则提供是一个迭代器顺序读取数组,使用代码如下:
1 | # ravel |
指定操作的维度
默认的sum、mean等操作是对数组中所有的元素进行对应的计算,如果只希望在某一个维度上或者几个维度上操作则需要设置其axis参数:
1 | arr1 = np.arange(12).reshape((2,2,3)) |
shape不同的array计算
多维数组之间的运算一般都要求参与运算的array的shape要保持一致,但是也有一些运算没有这样的限制:
- 矩阵乘法:矩阵的乘法需要用dot函数,满足矩阵乘法的要求即可
- 参与运算的一个数组的shape是其中另一个数组shape的一部分
1 | arr1 = np.arange(12).reshape((2,6)) |
添加和删减数组成员
这一部分对于我个人来说是最不熟悉的,因为在一般情况下创建新的数组然后赋值,同样也可以达到添加和删减的效果。只不过有时候赋值操作需要使用for循环来实现而无法直接完成,这个时候使用numpy数组提供的添加和删除操作就方便多了。
1. append操作
append操作原数组不变,返回的数组将变成一维,然后再后面追加元素:
1 | orig_arr = np.arange(12).reshape(2,2,3) |
append也可以沿着这某一个维度添加:
1 | orig_arr = np.arange(12).reshape(2,2,3) |
2. hstack操作
与append在axis设置为1时是一样的:
1 | orig_arr = np.arange(12).reshape(2,2,3) |
3. insert操作
insert操作实际上也是重新生成一个新的数组,它于append的区别是,append只能够再尾部添加,而insert能够指定位置添加,insert也可以指定纬度:
1 | ins_arr = np.insert(orig_arr, 1, 666) |
4. delete操作
同上delete是新生成数组而不是再原数组上删除,delete可以删除指定位置的元素,多维数组删除一个元素会退化为一维,也可以可以在指定纬度上的数据:
1 | del_arr = np.delete(orig_arr, 1) |
Mask Array
虽然mask数组在实际工作使用中得很多,但是有些细节还是不是很清楚,所以这里会注重一些使用中没有关注到的细节。
1. 运算优先级
mask数组一般由关系运算得到,对于很多关系运算符需要注意得是其运算优先级,生成的mask与原数组同shape
1 | nd_arr = np.arange(36).reshape((3,4,3)) |
2. 作为引索使用
使用mask可以得到子数组,但是多维数组在用mask引索得到得子数组是一维的:
3. 多个mask联合
可以多个mask联合使用,需要使用相应的逻辑运算函数:
1 | arr = np.arange(10) |
使用set_printoptions函数设置打印格式
在打印计算的结果的时候,最常见的一个问题是结果过小,显示的数字太长,不方便阅读,可以使用set_printoptions的precision参数设置显示精度,除此之外set_printoptions还有更多的设置:
1 | np.set_printoptions(precision=6) |