前言
最近在看深度神经网络论文的时候,遇到了STN这个名词完全不知道是什么东西,后面搜索后才知道这个原来是Spatial Transformer Network的缩写,一种能做空间变换的神经网络结构。这可让我长见识了,在我的认知中一直以为卷积神经网路就只是一层一层的做图像的特征提取,没想到空间仿射变换也能用神经网络去做。我觉得详细了解其实现细节对于我理解论文后面的内容是很有必要的,所以将学习的一些知识点记录在这篇文章中。
简介
Spatial Transformer Network是Google旗下的DeepMind的四位剑桥Phd研究员在2015年他们的论文中提出来的,他们针对CNN的特点,构建了一个新的局部网络层,称为空间变换层,它能将输入图像做任意空间变换。
我们知道在传统图像处理中空间变换是很重要的,因为图像本来就是空间中的物体在平面上的投影,而在不同视角得到的图像是不一样的,通过空间变换我们能够建立其相同场景在不同视角的位置和姿态的关系,在识别上我们希望我们的识别算法能够在各种不同的视角的图像识别出同样的物体。STN则为我们提供一种通过构建简单神经网络的方法来实现空间变换的方法,这样我们能够利用现有强大的神经网络训练方法来解决和优化各种空间变换问题,这是我个人觉得STN非常有价值的地方。
另外,STN 能够在没有标注关键点的情况下,根据任务自己学习图片或特征的空间变换参数,将输入图片或者学习的特征在空间上进行对齐,从而减少物体由于空间中的旋转、平移、尺度、扭曲等几何变换对分类、定位等任务的影响。加入到已有的CNN或者FCN网络,能够提升网络的学习能力。
STN原理
STN依赖如下三种传统图像处理技术:
- 仿射矩阵
- 逆坐标映射
- 双线性插值
放射变换矩阵
对平面图像放射变换矩阵就是一个2x3的齐次形式的矩阵,以此以实现平移、旋转、缩放、剪裁,这个传统空间变换的基本概念,这里就不细写了。
逆向坐标映射
这仍然是图像处理中常用的手段,当我已知一个空间变换的映射后,要得到目标图像,正向的方法是:对源图像做正映射从而得到目标。正映射的缺点是目标图像受限于原图,如当变换是带有放大操作时,目标图像必然会有某些像素点没有值,因为这些点的正变换在源图像中是没有点与之对应。所以更好的办法时做逆向坐标映射,逆向映射是正映射的反映射,使用逆向映射目标图像的任意点总能找到源图像中的位置或者坐标,当然这个坐标有可能是小数或者超出原图像的范围。
对于仿射矩阵,逆映射是正映射放射矩阵的逆矩阵。
双线性插值
承接上面逆向坐标变换图像放大操作的例子,在正向映射中为目标图像为空洞的那些像素点,在逆向映射中能够找到原图像中与之相对的位置的坐标,只是这些坐标带有小数,我们需要使用插值的方法对这些像素点进行补值,图像中插值方法最常用的就是双线性插值了。
双线性插值相对来说是一种比较简单但是有能保证一定质量的插值方法,公式这里就不写了。
STN网络结构
STN主要由三部分组成:
- localisation network
- grid generator
- sampler
下图为STN基本结构示意图
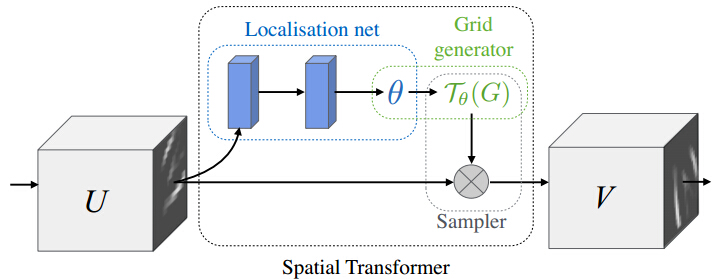
Localisation Network
Localisation Network可以翻译成定位网络,它的输入是feature map,输出就是仿射变换矩阵。在上面的示意图中,我们看到在Localisation Network画了两对象体,前面的作用是做计算,可以是全连接也可以是卷积,后面是回归层作用是将映射做归一化。
grid generator
grid generator的作用就是生成双线性插值的坐标网络,它实现的就是逆向坐标映射的结果。
sampler
sampler就是使用双线性插值的得到目标图的过程,作者也叫这一步Differentiable Image
Sampling,是希望通过写成一种形式上可微的图像采样方法,目的是为了让整个网络保持可以端到端反向传播BP训练。
总结
以上,具体结构还是的看原始论文,关于STN的初步内容就介绍完成,写的非常简略的原因是,我参考的大部分文章都对STN网络结构了解到非常深入的程度,所以我也怕写错,详细的东西如还是需要仔细看论文。