前言——从图像分类到物体检测
在深度学习领域卷积神经网络可以说是占了其半壁江山,不过卷积神经网络诞生之初只适用于图像分类问题,而然面对实际工程的各种需求,单纯的图像分类显然是远远不够,因此如何将卷积神经网络强大的体征提取能力应用到更复杂的问题上去,是当时乃至现在热门的研究主题。在这其中,R-CNN的出现让物体检测也成为了卷积神经网络的拿手好戏。
图像分类到物体检测与何区别?图像分类只是基本整个图像判别其种类,而物体检测则是读取图像的内容,不仅要识别其中有无特定种类的物体,还要得到其在图像中所处的大概位置。相对于图像分类的笼统、粗略,物体检测就要显得细致、具体得多了。
正如Alexnet的出现让人们认识到了卷积神经网络的巨大威力一样,R-CNN的出现也让卷积神经网络在物体检测上的精度大幅提高了一个档次。虽然后续的一系列物体检测网络,不断刷新着检测精度与运行的速度的榜单,但是R-CNN毕竟是一个开创者,在其后诞生了一系列R-CNN的改进版本,这足以说明其模型的经典性。由于R-CNN的论文比较经典,所以网上已经有不少论文的翻译,因此我就不会详细的分析论文了。在这里我希望通过本文,能够比较针对性的记录一下自己对R-CNN的理解与认识。
R-CNN的本质
从图像分类到物体识别是一个很有挑战的过程,R-CNN的思路是:从原始图像中取出不同区域作为独立的小图像,导入到CNN网络中做图像分类,从而将物体识别问题转化为分类问题。在这其中,R-CNN使用region proposal的方法代替传统的滑动窗口来生成小区域图像,将像生成的region图像resize到分类网络要求的尺寸,使用CNN来提取特征,最后借助线性SVM来分类。由于R-CNN结合了Region proopsal和CNN,所以就被取名为R-CNN: Regions with CNN features。
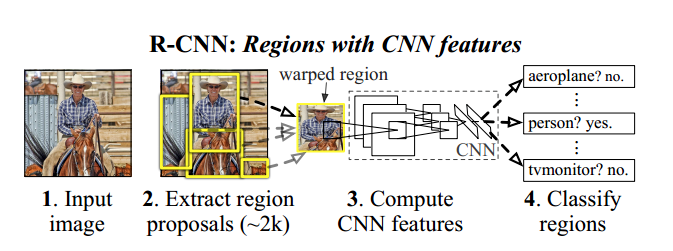
除此之外为了让识别的区域更加准确,R-CNN还加入了一个回归模型,用来提高Bounding-
box(区域矩形框)的精度。所以从整体上来看,R-CNN可以看成由如下三部分组成:
- Region proposal
- CNN+SVM分类
- Bouding Box线性回归
region proposal模块
在R-CNN中,组成其整体的三部分相对独立,region proposal更偏向传统方法,在R-CNN的中它更像是一步预处理步骤,它将生产的区域(Bouding Box)。原始论文中对region proposal的描叙相对较少,只是简单的提到了R-CNN中在众region proposal方法选取了selective search方法来使用。那么selective search是怎么工作的呢?这就只能查找关于selective search的相关论文了。在我个人看来,如果仅仅是关注深度学习这一块的话,确实是不必深究region proposal,因为这部分属于传统物体识别方法的大类,深入进去又是一个大坑,而且region proposal执行时间花销也不小,在后续的改进中版本的网络中,这部分都是主要被优化的对象,不过对于region proposal的大概原理还是有必要简单的了解以一下的。
selective search的目的就是生成在图像中可能有物体存在的区域位置的矩形框,由于它考虑了物体存在的可能性,从这个目标上来看,它比滑窗法(Sliding Window)生成的待选区域质量就要高得多。一般selective search会采样图像分割的技术,先将图像分成许多小区域,然后根据相似性将相似将相似的区域融合在一起,将子区域的矩形外界框作为bounding box输出。
在R-CNN测试阶段中region proposal模块会生成2000个区域(Bouding Box)输入到CNN网络中去,而在训练CNN时可以不用region proposal。
CNN+SVM分类器
R-CNN使用的CNN是AlexNet模型,输入227x227尺寸的RGB图像,最后的全连接层输出4096个特征的向量。而全连接层的存在也要求网络只能接受固定尺寸的图像,因此region proposal生成的区块需要全部缩放到227x227尺寸来。全连接层输出4096个特征的向量,导入到SVM分类器中,从而组合成一个完整的分类网络。
虽然在CNN与SVM联合组成一个分类器,但是在训练时却是分开训练的,先将CNN训练好,然后将CNN全连接层后面的分类部分换成SVM,然后再单独训练SVM。
1. CNN训练
对于R-CNN的CNN模块我们首先要知道的是,它是一个监督学习的网络,然而能够用于物体检测训练的数据却是比较少的,因此R-CNN在训练的时候采用了Supervised pre-training(预训练) + Domain-specific fine-tuning(特定数据集上微调)的方法来解决数据不足的问题。
在pre-training阶段,使用没有bounding box labels的ILSVRC2的数据集(1000个类别),而在fine-tuning的时候使用有bounding box labels的Pascal VOC数据集(21个类别),取Pascal VOC数据集图像中选取各类型的区域作为训练样本,正样本为与标注的bounding box重合区域(IoU)大于0.5的作为该类型的正样本,其余的为负样本。另外减小学习率,保证pre-training出来的参数不要变化太大。
2. SVM分类
这里不使用CNN直接分类,而还单独训练一个SVM分类器的原因:由于fine-tuning使用的数据量非常小,将IoU的标准卡严,很容易造成CNN过拟合,而降低IoU的标准,又导致CNN分类不准,所以使用一个适用于小样本分类的SVM分类器能够避免以上的问题。
R-CNN对每一种类型使用一个线性SVM分类器,因此又多少种类型,就又多少个SVM分类器,每一个SVM都会对的图像进行打分。
Bouding Box相关的处理
1. 挑选最好的Bouding Box
在测试时,region proposal可能会生成许多包含物体但是又过大或过小的Bouding Box,这些Bouding Box因为确实整体包含或者包含了大部分物体,所以会被分类器判别为真,但是我们肯定希望从中挑选出一个最好的Bouding Box,来作为我们检测到的唯一的结果输出。这里R-CNN选取SVM结果分数最高的最为输出结果。
2. 怎么处理多目标检测
仅仅选分数最高还无法处理多目标检测问题,如果一个图像上有可能存在多个检测的物体,那么仅仅取IoU最大的那个,一张图像将只能检测出一个物体。为解决这个问题,R-CNN使用的方法是,参考SVM输出的分数同时根据IoU的数值进行局部非极大值抑制,在一个图像中选出一个最好的Bouding Box,对于其周边的Bouding Box(IoU高的)去除,而对于其他IoU小的Bouding Box即使得分小也会保留,然后对剩下的Bouding Box重复上面的操作,直到选出所有目标。这样就即筛选出了局部最好的Bouding Box,同时不影响其他区域的检测。
3. Bouding Box线性回归
由region proposal生成的Bouding Box一般都不是完美包裹物体的矩形框,这是导致输出检测物体定位不精准的主要原因。因此在检测到物体之后,再对其输出的bounding box使用线性回归模型进行修正,其实质就是根据当前CNN输出的特征与当前的定位,来预测最好的bounding box(重心点与长宽)。当然回归模型也是需要单独训练的。